My First Attempt at ImageNet
ImageNet
If you haven’t heard of it, ImageNet is an image data set used for training image recognition systems. It’s substantially more challenging than the classic MNIST data set, and the ImageNet Large Scale Visual Recognition Competition (ILSVRC) has brought out the best of the best in machine learning research and produced some fantastic papers, so I decided to try my hand at making a model. All of my code is available on Github.
Inspiration
After seeing Google’s TensorFlow demo on Android, which I’ve blogged about already, I wanted to make my own version, but with a few alterations. Google’s version is trained to recognize the 1000 different classes used in the ILSRVC. However, these classes are not necessarily the most fun to recognize around the home or office. As much as I’d love to try their app on a container ship, I don’t think I’m likely to run into one any time soon, so I cut the number of classes down to 20 for my first version. This also make training and testing much faster, which is always great.
Getting the Images
ImageNet has a handy api that gives you a list of image urls for each class id. However, these list were made year ago and have not been maintained well, so a lot of error handling is required to handle dead links! Many links successfully returned Flickr’s “This image has been moved” image, but I found that checking for a minimum file size of 5kB and attempting to load each image after saving did a great job of weeding out any corrupted or missing links.
Loading Datasets
Now that all the images are downloaded, they are split into training, validation, and test datasets. After splitting, each dataset is normalized by subtracting the training set mean and dividing by the training set std deviation.
My Dataset class is a modified version of the one in TensorFlow’s MNIST tutorial in case you want a closer look.
Architecture
As a starting point, I copied my architecture almost entirely from the revolutionary AlexNet classifier. I highly recommend reading about AlexNet since it accomplishes an incredible amount without using overly sophisticated techniques, and many of its features can be found in more complex networks.
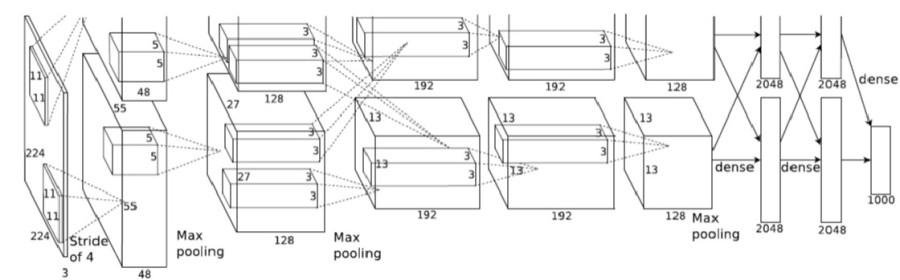
Anyway, the classifier has five convolutional layers and three fully-connected layers, and it has more than enough degress of freedom to fit the relatively tiny amount of training data that I have. Like I said earlier, I’ll have to work to reduce the overfitting this creates, but I found that creating an unnecessarily large model was a better first step.
Running the Model
My classifier script is based off of TensorFlow’s advanced MNIST tutorial, just with a lot more variables. When I started training this model, I found that my logits were in the billions, which meant that softmax always gave one class a probability of 1 and the rest zero. Since zero is technically the correct answer for 19 of the 20 classes, my model’s gradient didn’t produce any learning. Once I added batch normalization after each layer, my model immediately started learning. Basically, batch normalization prevents logit scores from plowing up towards the final layers, which prevents softmax from giving highly skewed answers.
Results
I found that after 15 minutes of training, the model got around 25% accuracy on the validation set. I’m incredibly happy with this as a starting point, and there’s plenty of room for improvement. First of all, this model shows tremendous overfitting, even with dropout. I plan to add data augmentation like translations, reflections, and maybe brightness adjustments to remedy this.
Another great idea is to reduce the number of parameters in this model since I’m fitting one fiftieth as many classes as AlexNet. This would aid with overfitting, not to mention the incredible speed boost. Once I have it working a bit better, I’ll throw it on a phone and take it around the office!
Let me know what you think, and I’d be glad to have suggestions on how I can make this better!